Content
What is meant by de-identification? Data de-identification involves removing or altering information that can lead to the identification of the source of the information. (You may see this described as a method of “disclosure avoidance”.) This matters because being able to identify the source (or “case”) creates potential risk for sharing sensitive, confidential, or other information that may not need to be public. The research data risk levels are based on how much harm the release of the data would cause to the individual and/or organization. Examples of harm from data include the sharing of medical or mental health records, sharing of unpopular or biased opinions, participation in illicit or illegal activities, and political activities. A release of confidential or sensitive information (including identifiable data) could also reduce trust and willingness to participate in research. Research Compliance, Integrity, and Security define related terms you might encounter when reading about de-identification both in the U.S. and overseas.
Frequently Asked Questions
What makes the data identifiable?
Unique identifiers and combinations of characteristics that are unique. For human subjects data, we are typically most concerned about Personally Identifiable Information (PII – see section on Sensitive Data). The best practice is to only retain the PII that is necessary to do the research. If you can aggregate any indirect identifiers, that reduces the identifiability of the data. For example, using age brackets instead of exact age (e.g. 65+ instead of 68), or Asian instead of specific country of origin. Geographic information is often the biggest concern, as it decreases the possible pool of candidates. Time is a concern for the same reason, so variables like “visit 1”, “visit 2”, etc. and time between visits (e.g. 13 days) is preferable to including November 2, 2002 at 9:00am. That said, during data collection, it may be better to use the more detailed information for better quality results. It is easier for people to provide more specific information (such as their age or zipcode) than to look through a list. And in logging data, there are auto-populate tools for time and date that reduce human error. In such cases, you would want to make the changes to reduce identifiability as soon as possible once data collection is complete.
De-identification only matters for human subject data, right?
To be clear – data identification is a particular concern for data from humans. But it may also be a concern for non-human data. And there are types of human data where it is NOT a concern. Information that is sensitive or highly unique or that has detailed location and/or time data increase concern, regardless of source. Anonymous data, data without (or with minimal) demographic characteristics, and data that is truly neutral and without cultural expectations are all characteristics that decrease concern with human subjects data. An inventory list of high cost equipment that includes location information is a greater concern than a dataset of people’s favorite ice cream flavor that includes their name. The risk is highly context dependent.
De-identification only matters if the data is being shared, right?
We also must try to reduce the risk of data stored in our systems, in case of a security breach. If you don’t need information for the research, you should remove it from any working datasets, and store the original data in a location with a security level to match the risk. (See EM42 and the research data risk classification tool for more on this.)
What if PII is part of the research?
We might have direct identifiers in a dataset as part of a contact method, or to need to link to other datasets. In these cases, the best practice is to create a random identifier that replaces the direct identifiers, with the file(s) connecting the two stored securely and separately from the research data. For indirect identifiers, you want to deidentify the data to the greatest extent while maintaining scientific utility. If these practices aren’t possible or data is still identifiable, then the data should be stored in a location to match the risk of the data. If data sharing is part of the project, efforts will need to be made to restrict access.
De-identification doesn’t apply to anonymous data, right?
Sometimes people use the term anonymous to describe data that could be identifiable. Data is only anonymous if no one (including the researcher or a data collection platform) can connect the data to the individual person. This includes the usual direct identifiers, but also IP addresses, and indirect identifiers. If a survey includes demographic questions, it is unlikely that anonymity can be guaranteed.
What does de-identification look like in practice?
There are a lot of different methods for de-identification, and the methods will depend on the type of data.
For qualitative text data, the most common methods include replacement and suppression. An example of this is replacing proper nouns with categories, like “Lincoln” with [city], or using ellipses (…) to indicate sections that have been removed due to the identifiability of the information. Qualitative text data can be challenging due to the combination of information across answers. The following resources provide examples and some guidelines for qualitative text data:
- Disclosure Review for Qualitative Research (a Census White Paper)
- Guide for Sharing Qualitative Data at ICPSR
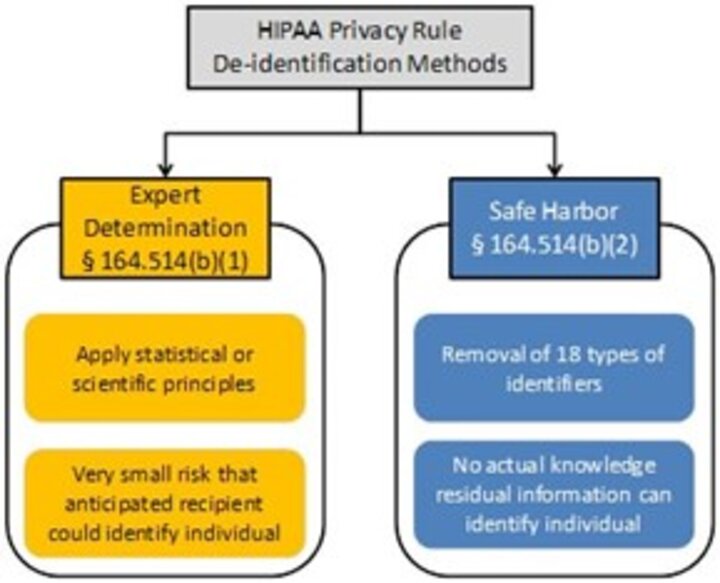
For quantitative data, there are a wide range of methods used. The most basic method includes removing any identifiable information not needed for the research. This is one of the methods approved for de-identification of HIPAA data, also known as the Safe Harbor method. Under the Safe Harbor method, 18 different types of direct and indirect identifiers are removed, leaving only sex, age, and the first three digits of their zip code (with the exception of 17 representing populations of <20,000 people).
Other methods include aggregation (aka generalization), and trimming of data. Aggregation involves changing single values into ranges (such as zip codes into states) while trimming reduces the number of less common values. Both of these methods can alter the resulting statistics, which should be assessed before finalizing any decision making.
There is also a method called differential privacy, which uses statistical methods to obscure identifiable information by adding “noise” to the data. The tradeoff is that it decreases statistical accuracy, particularly for smaller groups. This 3:17 minute video from the National Institute of Standards and Technology (NIST) explains differential privacy. This brief from the Census explains more about differential privacy as well as how the method compares to some other disclosure avoidance methods.
This technical brief from the National Center for Education Statistics provides detailed guidance and examples of how to report data in a way that does not lead to unintended disclosure. The Future of Privacy Forum created a visual guide that may be helpful in understanding more about deidentification.
Do datasets that have already been shared publicly need to be de-identified?
It depends. The thoroughness of de-identification is going to vary across datasets, and may also depend on the age of the data, as expectations have changed over time. If you are linking different data sources, the resulting dataset may have greater risk than the original datasets, and should be reviewed for risk. Something to consider is whether your dataset can be matched with public sources, such as voter registration records. Voter registration records are publicly available, and most commonly includes names, addresses, DOB, party affiliation, phone number, and email addresses. There are also vendors who collect consumer information. One of these, Alteryx, had a leak of “de-identified” data in 2017 that included 248 attributes per household for 120 million Americans. Technological advances such as machine learning is also a concern, but in assessing identifiability, you do not have to consider all future possibilities, just what a reasonable person in that community would be able to discover.
Are there guidelines for using random identifiers?
One of the most important guidelines is that the identifiers should be truly random and not based on information that can be decoded. Even using cryptographic algorithms may be insufficient if the data follows known formatting. A public NYC Taxi and Limousine Commission database that included individual trip information was made identifiable in 2014 due to the encrypted IDs being based on the known structures of the medallion numbers and the hack licenses. You could also consider abstractions of information, particularly if only used during data collection, like in social network research. Dombrowski et al. (2012) describe using the values of the last three numbers of a mobile phone number to help connect multiple data points and identify personal networks. Data that has a random identifier that can be linked to personal identifiers is called coded data.
Data use/access agreements
Should you need to obtain data from others, or collaborate during your data collection, you may need to obtain a data use or data access agreement. (A data use agreement is used when the data will be transferred and a data access agreement is used when the data will be used where it was stored – without transfer.) These agreements specify under what conditions the data may be used. This may include specifying users, storage and security requirements, rules for publishing with the data, data destruction protocols, etc. These agreements are also commonly used in the sharing and stewarding phases. Research Compliance, Integrity, and Security has a template for a data sharing and publication agreement between collaborators, and there is now an Agreements Module in NuRamp (learn more here).
Additional Resources:
Software for De-identification: A compilation of software and applications from Johns Hopkins Data Services. Includes resources for tabular and structured data, digital image de-identification tools, application/programming de-identification tools, and qualitative and unstructured text data.
De-identification of Data for Research Projects tip sheet: From UC Davis' Data Center of Excellence, the 4 page tip sheet provides explanations and examples of data management for de-identification.
Statistical Methods for Protecting Personally Identifiable Information in Aggregate Reporting: A methodological report from the Institute of Education Sciences. Focused on reporting, but provides examples of different types of data redaction and possibilities of identification that are relevant to data de-identification.