Content
Most data has flaws that impact how well it meets the needs of the research. This doesn’t mean it can’t be used, just that it should be assessed to be able to understand the limitations and what can be done. Data analyses yield the most reliable results when the data is properly prepared and of best quality.
Data quality can have many meanings, but here, in the context of research data quality and the data life cycle, we mean the degree to which the data is usable and fits the intended purpose. Characteristics that may be assessed include “accessibility, amount of data, believability, completeness, concise representation, consistent representation, ease of manipulation, free of error, interpretability, objectivity, relevancy, reputation, security, timeliness, understandability, and value-added” (Wang et al. (2022) pg. 5). It is expected that these expectations will vary by discipline and specific types of research.
If the research involves primary data collection (i.e. you are collecting the data yourselves), the process of data quality starts before data collection begins. On the measurement side, you need to consider if the data point being collected meets the goals, if the data point is measured in a way that best meets the goals of the research, and that the data was entered/processed/edited in a way that was accurate and again, meets the goals of the research. Data quality also includes where the data comes from, broadly called representation. Consider whether the data is meant to be generalizable beyond the source of the data, and whether your data source(s) is sufficient to represent a larger population, and whether there are patterns to missing data. For human subjects data, you would not collect data at UNL and then be able to generalize to college students in Nebraska. Similarly, irrigation data collected in Sheridan County would not be used to generalize to farming across the state.
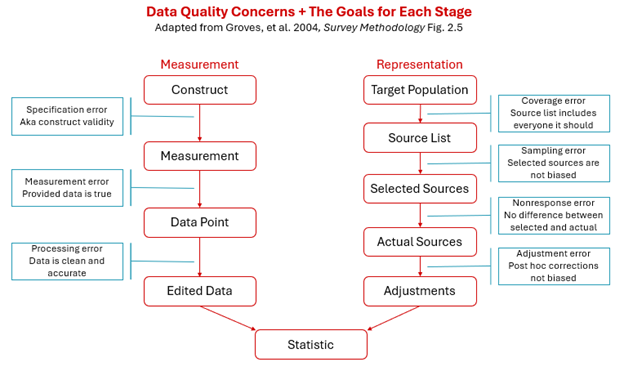
When the research involves secondary data (i.e. data collected by others), the same concerns apply, but researchers do not have the ability to change the data/process. Once assessing what was done, the researcher should consider how well the data meets the different data quality concerns, and decide whether the data is sufficient to meet the needs of the research. In some cases, your options will be limited by resources (time and money) and the availability of data. In such cases, if the data is not the best fit, you should discuss the limitations of the data in research outputs.
Some actions that can be taken to assess data quality include (in no particular order):
- Comparing the data to similar others
- Comparing data sources to benchmarks, if available
- Looking for patterns of missing data
- Comparing results with and without adjustments
- Check to make sure variables are coded consistently
Another part of data quality is data cleaning – this makes it fit for your use. Data cleaning refers to the stages of data preparation required before analyzing the data. Secondary data should have already gone through this process, but you will want to verify that the starting dataset is prepared the way you need before moving on to analyses.
The following are common examples of data cleaning activities, when applicable:
- Removing unnecessary identifiers.
- Removing cases that were part of testing, duplicate entries, cases without usable data, cases without consent.
- Making sure missing data is coded appropriately.
- Checking for impossible/improbable values. For example, a question that asks about the number of days in the last week and there are answers >7, or when someone says they drank 150 drinks on a typical Saturday.
- Checking for and making decisions about outliers.
- Making sure text entry data is formatted correctly. Examples of this include changing ages written as words into integers (twelve --> 12), removing decimal points, or deleting partial zip code entries.
- Making sure all numerical values use the same metrics. For example, data on time, weight, length, currency, temperature, etc. may all be entered into different types of units.
- Checking the coding of partially closed ended responses (such as other, please specify).
- Making decisions about bad faith answers. Bad faith answers are responses that do not appear to be a sincere attempt to answer the question asked.
- Making decisions about whether to remove cases due to poor data quality.
- In online data collection, looking for evidence of bots.
- Creating new versions of variables to meet analytic/reporting needs.